爬取有道翻译界面JSON解析
Contents
为什么要JS解析?
刚开始学习爬虫的时候,我练习的案例主要是通过Requests库请求一些简单的网页,或者通过Selenium自动化工具来抓取页面渲染过后的数据。使用Selenium最大的缺点就是:慢、效率低。因为Selenium爬取网页是通过模拟人对浏览器的行为,来实现数据的爬取的。对于数据量比较少的,Selenium还是可以胜任,但是如果爬取的数据量很庞大,那么用Selenium来进行数据的爬取显然是不合适的。
鉴于Selenium爬取效率低下的问题,让我们回到一个最初始的问题:为什么要爬虫?
显然,我们做爬虫程序就是为了获取互联网上的资源,狭隘的讲是获取HTML页面上的数据,而HTML数据是服务器对客户端请求响应生成的。那么爬虫问题归根结底就成为了:**如何给服务器成功发送请求?**的问题。
客户端给服务器发送请求,便属于HTTP协议范畴,在这里不细讲。简单来说:客户端需要给服务器发送一个信息包(请求头部信息+请求数据信息),头部信息会告诉服务器(我是谁、我需要什么类型的数据等等),请求的数据信息则会告诉服务器你想要哪一个数据的信息(比如:我想知道world中文翻译的信息,那么数据信息里面就包含了world这个单词)。
虽然 请求 = 请求头+数据信息 ,但是服务器为了自身的安全性考虑,并不会直接接收 world 这个单词,而是接收加密后的字符串再返回响应结果。这就是 JS加密:当我们在浏览器中输入某一个关键字时,JS代码会先进行加密,然后将加密后的信息放在 请求 里面发送给服务器。 所以为了爬取有道翻译,我们最先要解决的便是如何知道我们输入一个单词(world),有道翻译界面是如何把单词加密的,这便是 JS解析。只有拿到加密后的数据放到请求里面发送给有道翻译服务器,才能成功获得响应数据。
JS解析的一般步骤
JS解析的目的:获取每次输入关键字后,加密后的数据。所以最关键的目标就是找到加密的方式——JS代码。
-
查看请求的数据参数有哪些
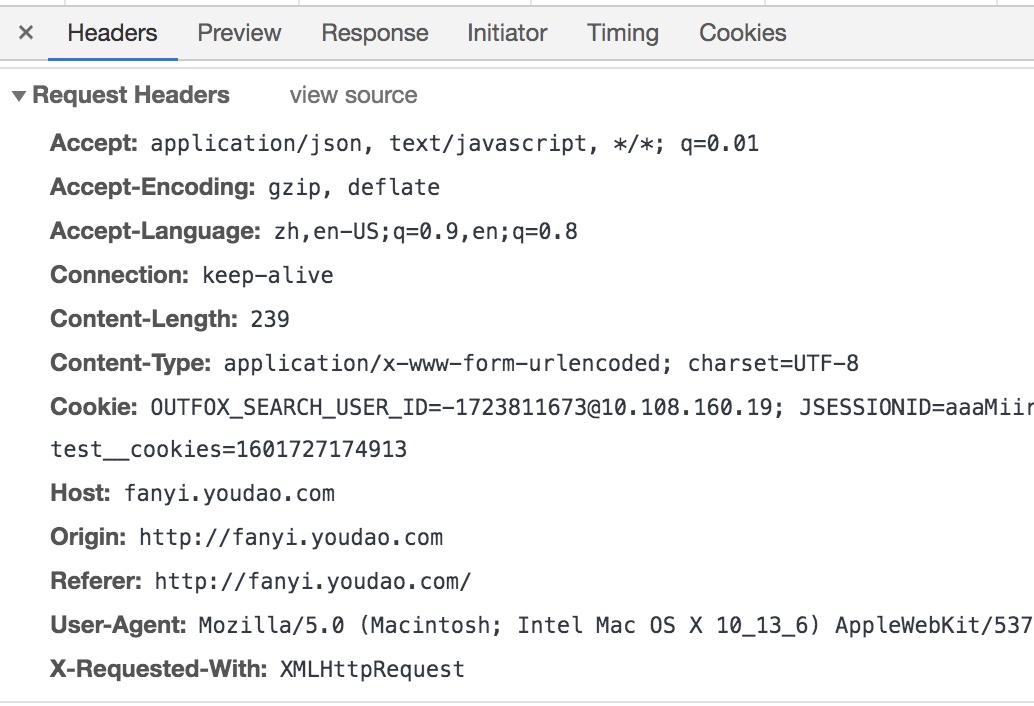
请求头信息
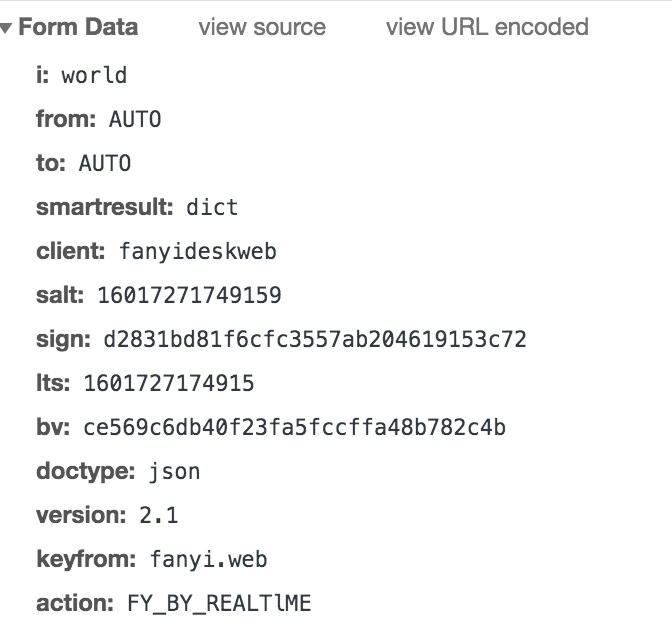
输入world时,请求的数据信息
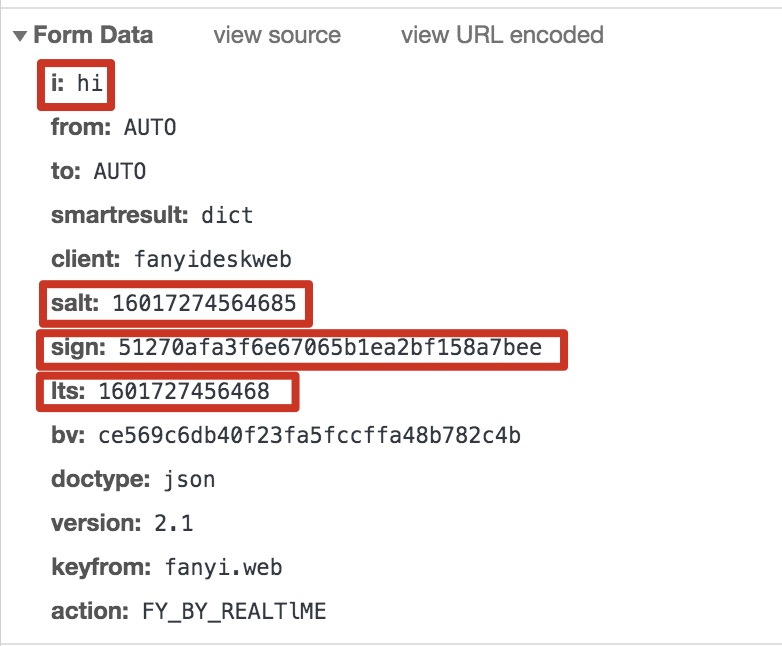
输入hi时请求数据信息
对比发现:world请求信息 与 hi请求信息 只有i、salt、sign、lts四个参数不同。i代表查询的单词这个很明显,剩余的3个参数时如何生成的呢?
-
**JS数据解析 **
在 Initiator中点击js代码(如果一开始不知道点那个,就慢慢试一试吧)
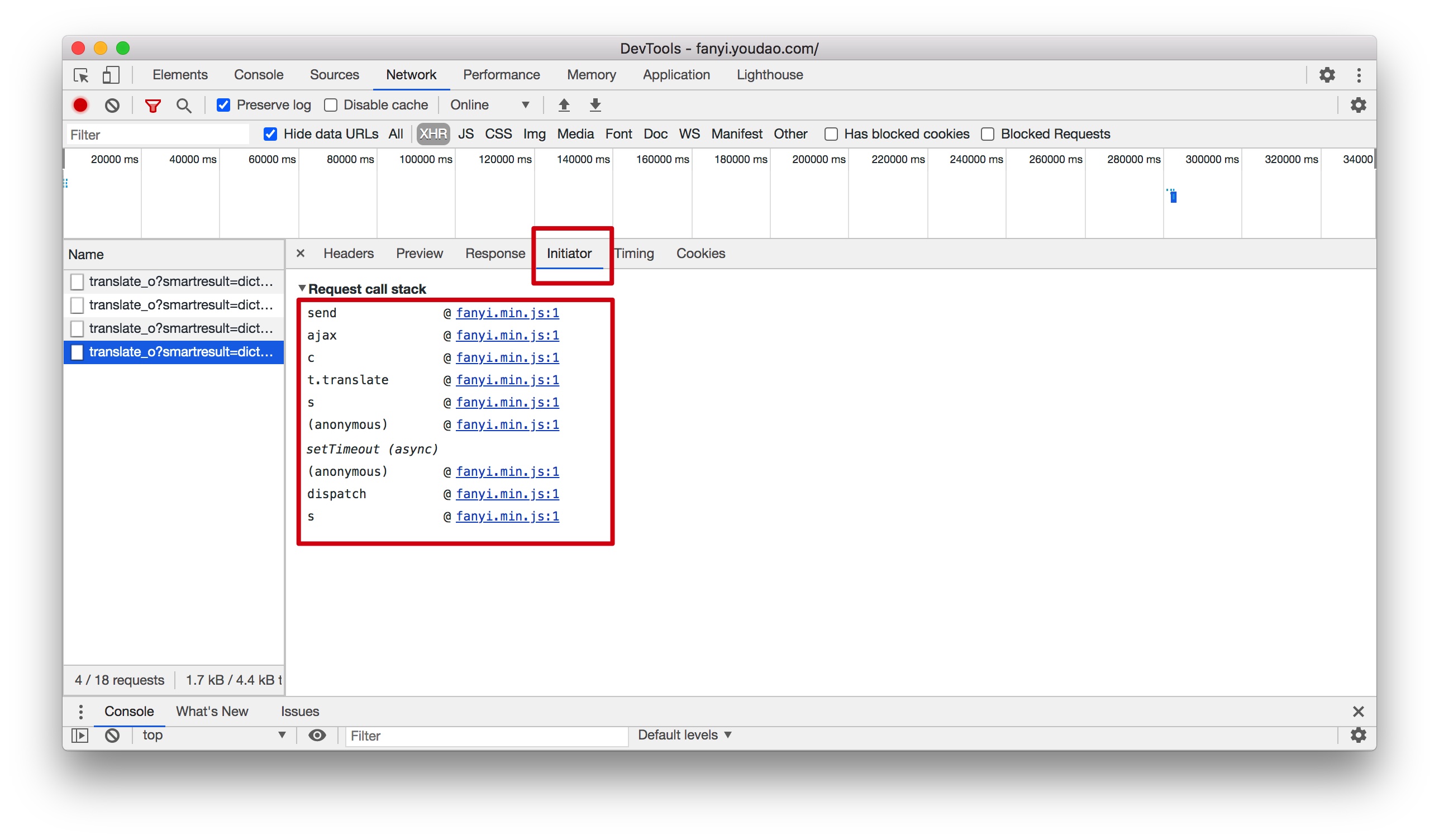
然后搜索前面找到的参数,找到对应的JS函数
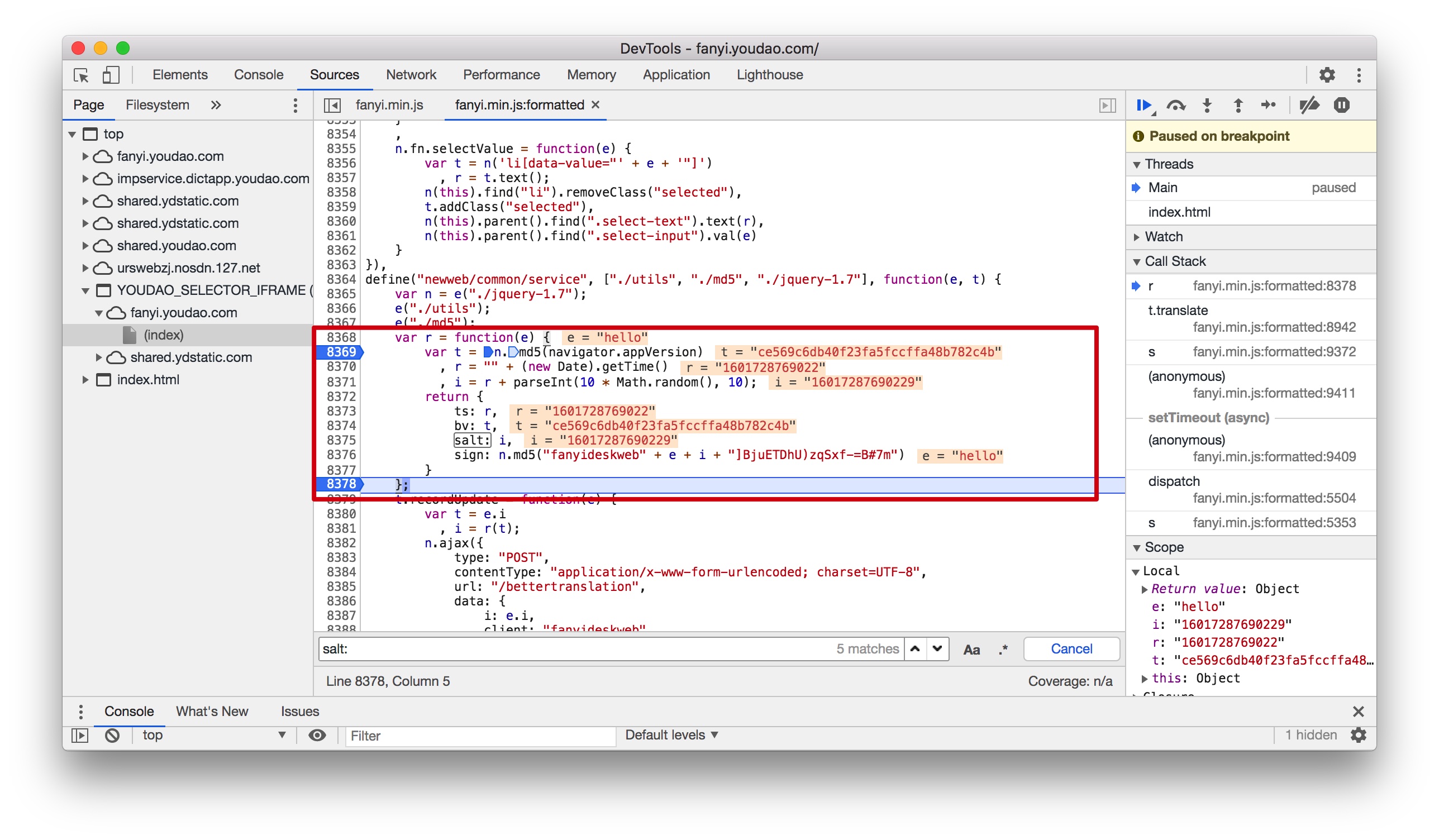
通过对上面红色框框里的JS函数代码分析,可知道:
- ts:r是获得当前的时间戳
- salt:i是当前时间戳+[0,9]之间一个随机数
- sign:对(“fanyideskweb” + e + i + “]BjuETDhU)zqSxf-=B#7m”)MD5加密,e代表输入的单词,i是salt值。
-
python代码实现JS函数功能
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15""" 获取请求data中 ts、salt、sign参数值 word:为输入的单词 return:返回data参数 """ # word = input("请输入查询的英文单词:") #### 生成字符串时间戳 lts = str(int(time.time()*1000)) #### salt值 salt = lts + str(random.randint(0, 9)) ### MD5加密 string = "fanyideskweb" + word + salt + "]BjuETDhU)zqSxf-=B#7m" m = hashlib.md5() m.update(string.encode('utf-8')) sign = m.hexdigest()
完整代码
|
|
总结
通过学习有道翻译界面的爬取,是自己第一次进行JS解析,然后再爬取数据。这个例子让我深刻理解了HTTP请求的流程,以前只是局限于书中介绍的一些知识点。其实真实的HTTP请求中,是先通过JS函数对数据加密,然后再添加再请求数据包里面。这也是目前绝大部分网站反爬虫的主要手段。