机器学习之基本概念
Contents
###基本术语
根据训练数据是否拥有标记信息,机器学习任务可大致划分为两大类:监督学习(supervised learning) 和 无监督学习(unsupervised learning)。
- 监督学习:分类和回归。
- 无监督学习:聚类。
机器学习的目标是使学得模型能 很好地适用于 新样本,而不仅仅在训练样本上工作的很好。学得的模型适用于新样本的能力,称为 泛化能力(generalization ability)。具有强泛化能力的模型能很好的适用于整个样本空间。
通常假设样本空间中的全体样本服从一个未知的 分布(distribution)$D$,我们获得的每个样本都是 独立地 从这个分布上采样获得的,即 独立同分布(independent and identically distributed,$i.i.d$)。一般而言,训练样本越多,我们获得的关于 $D$ 的信息越多,学得模型泛化能力越强。泛化能力强弱对应着学习器对新的数据集归类精度的高低。
假设空间
假设空间由样本 所有可能的属性 及其 可能的属性值 张成的空间。
例如要通过 “色泽,根蒂,敲声” 3个属性来判断一个西瓜是 “好” or “坏”(这里假设西瓜只有3个属性)。对于3个属性可能取得属性值见表1.1

在表第一行:“色泽=青绿^根蒂=蜷缩^敲声=浊响” 归类为好瓜。这是已经见过的瓜,如果 “色泽=浅白^根蒂=蜷缩^敲声=浊响”,怎么办?
我们可以把学习过程看作一个在所有假设(hypothesis)组成的空间中进行搜索的过程。对于这个例子而言,色泽=?^根蒂=?^敲声=? 3种属性所有可能性的取值构成了西瓜的假设空间。
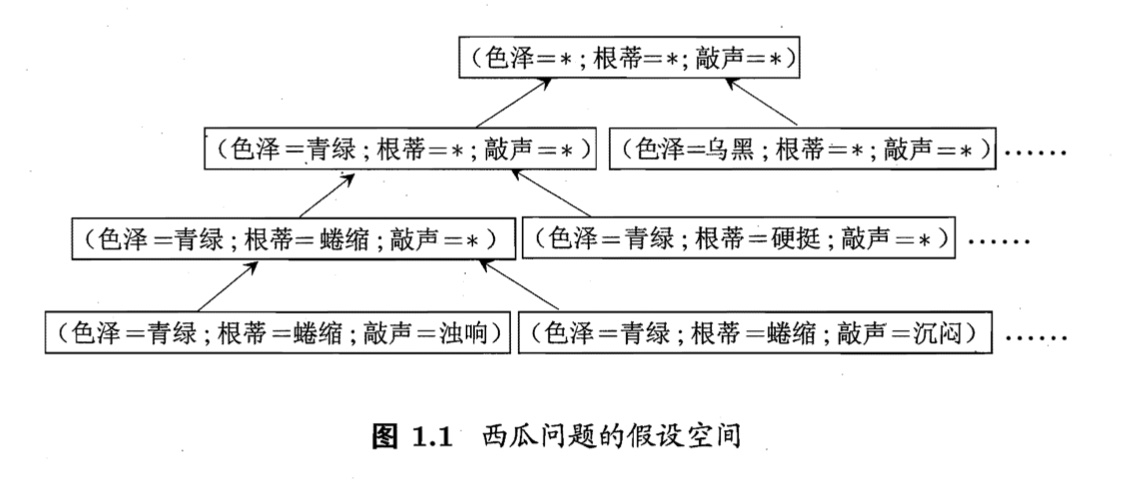
现实问题中我们常常面临很大的假设空间,但学习过程是基于有限样本训练集进行的,因此,可能有多个假设与训练集一致,即存在着一个与训练集一致的 假设集合,称之为 版本空间(version space)。
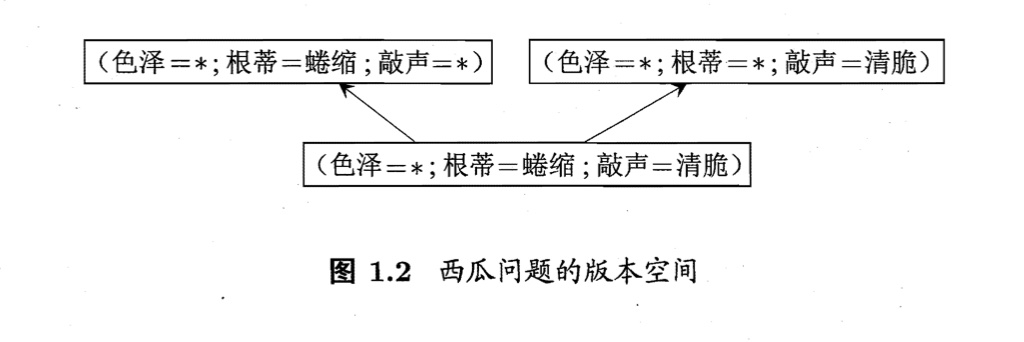
归纳偏好
通过学习得到的模型对应了假设空间中的一个假设。于是,图1.2的西瓜版本空间给我们带来一个麻烦:现在有3个与训练集一致的假设,但与他们对应的模型在面临新样本的时候,却会产生不同的输出。
例如,(色泽=青绿;根蒂=蜷缩;敲声=沉闷)这个新瓜,不同的模型会给出不同的分类。那应该采用哪一个模型(假设)呢?
如果仅有表1.1中的训练样本,则无法断定上述3个假设哪一个更好。对于一个具体的机器学习算法,它必须要产生一个模型,这时算法本身的 偏好 就会起到关键作用。
- 如果算法喜欢 尽可能特殊,则算法会选择 *“好瓜 – (色泽= )八(根蒂=蜷缩)八(敲声=浊晌)" 属性标记详细的模型。
- 如果算法喜欢 尽可能一般,由于某种原因,它更相信根蒂,则它会选择 **“好瓜 – (色泽= *) ^(根蒂=蜷缩)八(敲声= *)” ** 模型。
机器学习算法在学习过程中,对某种类型假设的偏好,称为 归纳偏好(inductive bias)。一般情况下,根据 奥卡姆剃刀原理(Occam’s Razor):如无必要,勿增实体 来引导算法确立 “正确的” 偏好。
NFL(No Free Lunch Theorem)定理
在所有问题出现的机会相同、或所有问题同等重要下,所有算法的期望性能都是一样的。
NFL定理假设了所有可能的目标函数 $f$ 是一个均匀分布,即所有基于数据集的假设都是等价的。NLF定理最重要的寓意,是让我们清楚地认识到,如果脱离具体问题(有些假设不常见,或许在实际问题中不存在),空泛地谈论 什么学习算法更好 毫无意义。
参考资料
- 《西瓜书》第一章